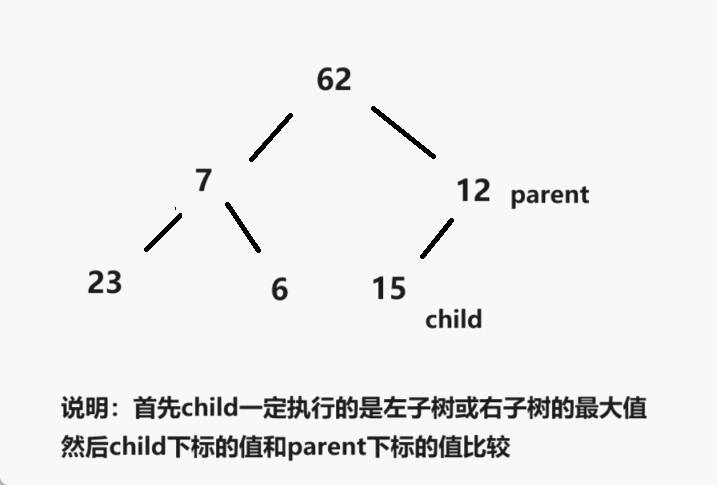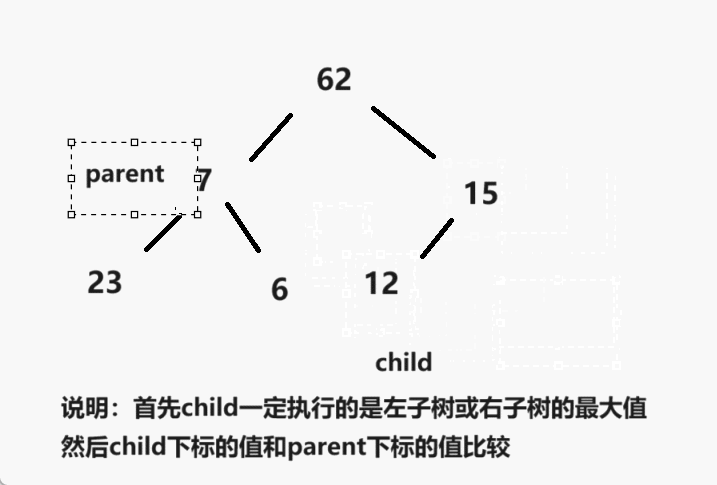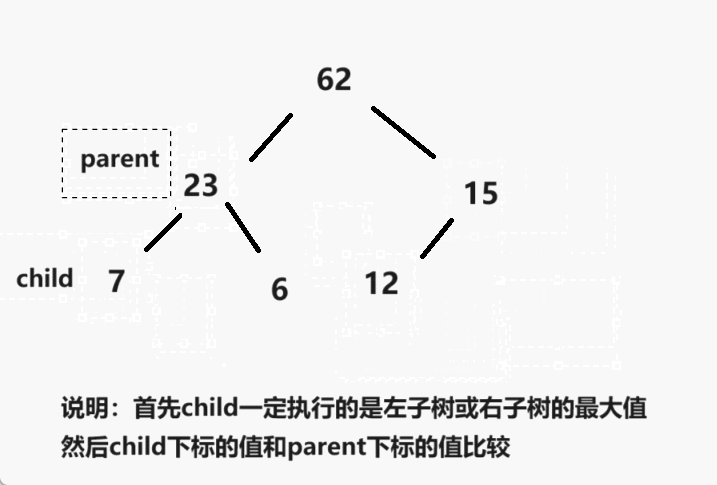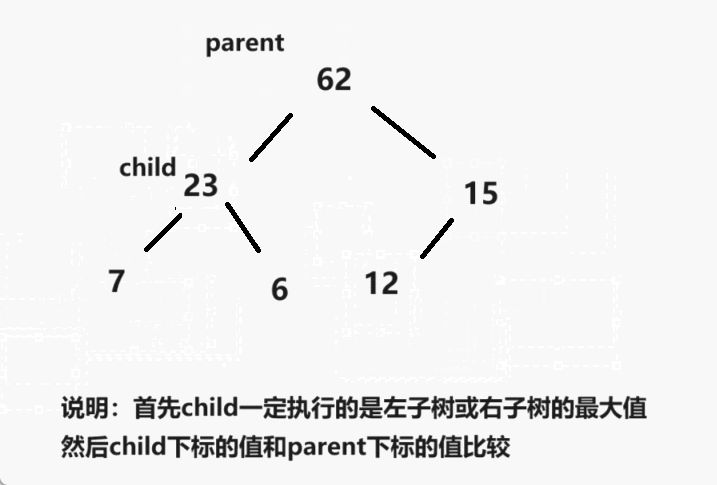
表锁和行锁?
表锁:
- 表锁是对整个表进行加锁,可以分为表共享读锁(表读锁)和表独占写锁(表写锁)两种模式。
- 在表级锁中,读锁之间不互斥,但写锁和任何其他锁都互斥。
- 表锁粒度大,锁定的资源范围广,会导致并发性能较差,但是对于大量小事务来说,管理成本较低。
行锁:
- 行锁是对数据库表中的行记录进行加锁,只锁定指定行的资源。
- 行锁可以减少锁冲突,提高并发性能,但也容易出现死锁情况。
- InnoDB存储引擎支持行级锁,通常通过索引实现,当没有合适的索引时,可能会升级为表级锁。
- 行锁分为共享锁(读锁)和排他锁(写锁)。多个事务可以持有共享锁,但是排他锁之间互斥
间隙锁?
间隙锁是用于锁定某一范围内的数据之间的间隙,而不是实际存在的数据记录。它的作用是为了防止其他事务在该范围内插入新的数据,从而确保事务的隔离性和一致性。
举个例子,假设有一个范围查询条件为WHERE age BETWEEN 20 AND 30,事务A执行该查询并获得了间隙锁,这意味着其他事务无法在20到30之间插入新的数据,即使当前并不存在这样的记录。只有事务A释放了间隙锁,其他事务才能在这个范围内插入新的数据。
间隙锁在一些场景下非常有用,特别是在防止幻读(Phantom Read)的情况下,可以确保范围内的数据不会被其他事务修改或插入,从而提高了并发事务的可靠性。
间隙锁在数据库中有几个重要的应用场景:
-
防止幻读(Phantom Read):幻读指的是在一个事务中多次执行相同的查询,但结果集却发生了变化,通常是由于其他会话对查询范围内的数据进行了插入或删除操作。通过使用间隙锁,可以防止其他会话在查询范围内插入新的数据,从而避免了幻读问题。
-
保证唯一性约束:间隙锁可以保证在并发环境下,不会出现多个会话同时向同一个范围插入相同值的情况。如果没有间隙锁,可能会导致数据唯一性约束的破坏。
-
避免脏写:间隙锁可以避免多个会话同时更新同一个范围内的数据,从而保证了事务之间的隔离性。如果没有间隙锁,可能会导致脏写问题,即多个事务同时修改同一范围内的数据,最终结果可能是不可预测的。
-
支持范围查询的一致性:间隙锁可以确保在一个事务中对某个范围进行查询时,其他会话不能同时插入相同范围的数据,从而保证了范围查询的一致性。
索引、聚集/非聚集、覆盖、回表查询?
-
索引:索引是一种数据结构,帮助数据库引擎快速定位数据。它类似于书籍的目录,可以根据关键词快速找到所需内容。索引可以是唯一索引,用于确保数据的唯一性。
-
聚集索引:聚集索引中,叶子节点存放的是实际的数据记录,而不是指向数据的指针。这种索引的叶子节点是按照一定规则排列的,类似于书籍中章节的排列,所以也被称为"聚集"索引。
-
非聚集索引:与聚集索引相反,非聚集索引中叶子节点不包含实际的数据记录,而是指向数据的指针。这样的索引与实际数据分开存放,索引本身是一种目录,数据是另一种结构。
-
二级索引:在InnoDB等数据库中,除了主键索引外的所有非聚集索引都被称为二级索引。这些索引的叶子节点存放的是对应记录的主键值,而不是实际的数据。
-
覆盖索引:当查询的数据列都包含在索引中时,数据库引擎只需要通过索引就能够获取到所需的数据,而不需要再读取实际的数据行。这样的索引被称为覆盖索引,可以大大提高查询性能。
-
回表查询:当查询条件无法完全通过索引获取所需数据时,数据库引擎需要先通过索引定位到相应的数据行,然后再根据主键值或指针去聚集索引中获取实际的数据。这个过程被称为回表查询,可能会导致额外的IO操作和性能损耗。
索引优缺点和适用条件?
优点:
- 加快检索速度: 索引可以大大加快数据的检索速度,特别是对于大型数据表而言。
- 保证数据一致性: 唯一索引可以保证数据的唯一性,确保数据的一致性。
- 避免排序: 索引可以避免对数据进行排序操作,提高查询效率。
- 加速表连接: 当进行表连接操作时,索引可以显著加速查询的执行速度。
缺点:
- 占用物理空间: 索引需要额外的物理空间存储,特别是对于大型数据表而言,可能会占用较多的磁盘空间。
- 降低增删改效率: 对数据进行增删改操作时,索引也需要相应地进行更新,这可能会降低增删改操作的效率。
- 创建维护耗费时间: 创建和维护索引需要耗费一定的时间和资源,特别是对于大型数据表而言,可能会比较耗时。
适用条件:
- 有唯一性限制: 当需要保证数据的唯一性时,可以使用唯一索引。
- 常用 WHERE 条件: 当某个列经常出现在 WHERE 子句的条件中时,可以考虑为该列创建索引。
- 常用 GROUP BY 和 ORDER BY: 当某个列经常出现在 GROUP BY 和 ORDER BY 子句中时,可以考虑为该列创建索引。
不适用条件:
- 大量重复数据: 如果数据表中存在大量重复的数据,创建索引可能不会带来明显的性能提升。
- 数据量少: 当数据量比较少时,索引可能会增加额外的开销,而带来的性能提升并不明显。
- 经常更新: 当数据表经常进行增删改操作时,频繁的更新索引可能会带来性能上的损失,甚至影响到整体的数据库性能。
索引什么时候会失效?
索引可能会失效的情况有很多,包括:
- 条件中包含 OR 操作符: 除非所有 OR 条件列都有索引,否则索引可能会失效。
- LIKE 查询以 % 开头: 当 LIKE 查询以 % 开头时,索引可能会失效,但以 % 结尾时索引通常有效。
- 多列索引未使用最左前缀: 如果创建了多列索引,但查询未使用索引的最左前缀部分,索引可能会失效。
- 在索引列上使用函数或表达式: 如果在索引列上使用函数或表达式,索引可能会失效。
- 使用非等于操作符: 当在索引列上使用非等于操作符(如 <、>、!= 等)时,索引可能会失效。
- 使用 OR 操作符: 在索引列上使用 OR 操作符时,索引可能会失效。
- 使用前缀索引: 如果创建了前缀索引,但查询未使用索引的完整前缀,索引可能会失效。
- NULL 值的处理: 对于索引列,如果查询中涉及 NULL 值的处理不当,可能会导致索引失效。
为了避免索引失效,关键在于遵循以下原则:
- 尽量使用等于操作符和 AND 操作符。
- 确保查询使用了索引列的最左前缀。
- 避免在索引列上使用函数、表达式或非等于操作符。
- 避免使用 OR 操作符。
- 确保查询中使用的值与索引列的类型一致。
- 对于 LIKE 查询,尽量避免以 % 开头,或者考虑使用全文索引等替代方案。
- 谨慎处理 NULL 值,确保查询中对 NULL 值的处理与索引的定义一致。
如何优化索引?
-
确定查询条件: 在优化索引之前,首先需要仔细分析查询条件。确定查询频率高的、对性能影响大的查询条件是关键。这些查询条件可能是等值查询、范围查询或排序/分组操作等。
-
选择合适的列作为索引: 选择合适的列作为索引列至关重要。通常选择那些频繁用于查询条件、过滤条件或连接条件的列作为索引列。同时,应该选择具有高基数(区分度)的列,以便索引能够更有效地过滤数据。
-
考虑多列索引: 在一些复杂的查询中,可能需要同时查询多个列。这时可以考虑创建多列索引,以覆盖多个查询条件。多列索引可以减少索引的数量,提高查询效率。
-
避免过多的索引: 过多的索引会增加数据库的存储和维护成本,并且可能会降低写操作的性能。因此,应该避免创建过多的索引。在创建索引之前,要仔细评估索引的必要性和对性能的影响。
-
定期维护索引: 索引需要定期维护以保持其性能。这包括删除不再使用的索引、重新组织索引以减少碎片化、更新索引统计信息以保持其准确性等。
-
分析查询和执行计划: 通过分析查询和执行计划,可以了解查询是如何使用索引的。这可以帮助识别潜在的性能瓶颈,并进行相应的调整和优化。
-
使用覆盖索引: 覆盖索引是一种特殊的索引类型,它包含了查询中需要的所有列。这样,在查询执行时,数据库可以直接使用索引而无需回表查询数据行,从而提高查询性能。
-
避免锁竞争: 在优化索引时,需要注意避免锁竞争对性能的影响。特别是在大型表上操作时,应该尽量减少长时间持有锁的情况,以允许其他事务能够并发执行。
mysql如何实现索引?
MySQL 使用不同类型的索引来优化查询性能,而 InnoDB 存储引擎则主要采用 B+ 树索引结构来支持索引功能。
1. B+ 树索引结构
MySQL 中的索引通常使用 B+ 树(B-tree)或 B+ 树的变种。B+ 树是一种平衡树数据结构,能够快速地支持按键查找、范围查找和顺序访问。
- B+ 树特点:
- 内部节点存储索引键值和子节点指针,叶子节点存储索引键值和指向对应数据行的指针。
- 叶子节点使用双向链表连接,便于范围查询和顺序遍历。
2. InnoDB 索引类型
InnoDB 存储引擎支持多种索引类型,包括主键索引(聚集索引)和辅助索引(非聚集索引)。
-
主键索引(聚集索引):
- InnoDB 表中的每张表都必须有一个主键索引。
- 主键索引的叶子节点存储的是整行数据,因此称为聚集索引。
- 数据行按照主键的顺序存储,因此主键索引能够加速按主键的查询和范围查询。
-
辅助索引(非聚集索引):
- 辅助索引叶子节点存储的是索引列和对应的主键值。
- 当使用辅助索引查询时,需要先根据辅助索引的值找到主键值,再通过主键值找到对应的数据行。
3. 索引的创建和维护
MySQL 中可以通过 CREATE INDEX 或 ALTER TABLE 语句来创建索引。索引的维护包括更新索引统计信息、重建索引以减少碎片化、删除不再需要的索引等操作。
- 索引优化策略:
- 选择适当的索引列,避免创建过多或不必要的索引。
- 定期维护索引,确保索引的性能和有效性。
- 分析查询执行计划,优化查询语句以充分利用索引。
4. 索引的使用和注意事项
-
使用覆盖索引:
- 利用覆盖索引可以减少回表操作,提高查询性能。
-
避免过度索引:
- 过多的索引会增加数据修改的成本,降低写入性能。
使用 B+ 树作为索引的主要原因
-
减少 IO 次数: B+ 树相比于 B 树能够减少 IO 访问次数。在 B+ 树中,非叶子节点只存储索引信息而不存储实际数据,因此每个节点能够容纳更多的索引键值,使得树的高度更低,从而减少了访问磁盘的次数。
-
优化范围查找: B+ 树通过叶子节点之间的链表连接来优化范围查找。由于叶子节点存储了整个索引的键值,通过叶子节点的双向链表可以高效地遍历整棵树,从而提高了范围查询的效率。
-
优化增删效率: B+ 树相比于 B 树在插入和删除操作时具有更高的效率。由于非叶子节点只存储索引信息,而叶子节点之间通过链表连接,插入和删除操作不需要更新非叶子节点的内容,因此可以减少更新的开销,提高了增删操作的效率。
-
有序数组链表结构: B+ 树的叶子节点采用有序数组链表结构,使得范围查询和顺序遍历更为高效,同时也降低了数据的碎片化程度。
MyISAM 和 InnoDB 存储引擎中,它们对 B+ 树的实现方式有一些关键区别
1. MyISAM 实现 B+ 树的方式:
-
非聚集索引: MyISAM 使用非聚集索引,其中叶子节点存储的是数据行的物理地址而不是数据本身。
-
叶子节点存放地址: 在 MyISAM 中,叶子节点的数据部分存放着对应数据行的物理地址,而不是数据本身,因此需要通过物理地址再次查找到对应的数据行。
2. InnoDB 实现 B+ 树的方式:
-
聚集索引: InnoDB 使用聚集索引,主键索引即为聚集索引,叶子节点存储的是数据行本身。
-
数据行存放数据: 在 InnoDB 中,叶子节点存储的是数据行本身,而非物理地址。因此,通过主键索引查询时,可以直接获取到数据行的内容,而无需额外的查找过程。
-
辅助索引: 对于非主键索引,InnoDB 存储的是索引列的值和对应的主键值,而不是物理地址。这些辅助索引通过主键值来定位对应的数据行。
-
自增 ID 主键优化: 在 InnoDB 中,使用自增 ID 作为主键时,新插入的记录会顺序添加到当前索引节点的后续位置,而不会导致频繁移动索引页,从而提高了插入效率。
针对慢查询问题
-
命中索引: 检查慢查询是否没有命中索引。如果没有命中索引,可以通过分析查询语句和表结构,优化查询语句并创建适当的索引来提高查询效率。
-
删除冗余列: 如果查询涉及到了冗余列,可以考虑修改查询语句,去除不必要的冗余列,从而减少数据传输量和查询时间。
-
建立索引: 对于需要的查询字段,确保表上有相应的索引。使用合适的索引可以大大提高查询性能。
-
横向纵向分表: 如果数据量过大,单表查询性能下降,可以考虑对表进行横向或纵向分表。横向分表将大表按照某种规则拆分成多个较小的表,纵向分表则是将大表中的列按照某种规则划分成多个较小的表,以提高查询效率和减少锁竞争。
优化 MySQL 性能
-
创建索引: 为经常用于搜索和筛选的字段创建索引,可以大大提高查询效率。但要注意不要过度索引,因为每个索引都会增加写操作的开销。
-
*避免使用 Select : 明确列出需要查询的字段,而不是使用 Select *。这样可以减少从数据库读取的数据量,提高查询速度,并减轻数据库服务器的负担。
-
垂直分割分表: 将大表按照某种规则划分成多个较小的表,可以减少单个表的数据量,提高查询性能。例如,将不同的业务字段拆分成不同的表,或者将经常使用的热数据和不经常使用的冷数据分开存储。
-
选择正确的存储引擎: 根据应用场景和需求选择合适的存储引擎。InnoDB 适用于大多数应用场景,支持事务和行级锁,适合于高并发和大量写入的场景;MyISAM 适合于读密集型的场景,但不支持事务和行级锁。
-
优化查询语句: 通过分析慢查询日志,优化频繁执行的查询语句,包括重写查询语句、使用合适的索引、避免全表扫描等,以提高查询效率。
-
调整数据库参数: 根据服务器硬件配置和数据库负载情况,调整 MySQL 的配置参数,包括缓冲池大小、连接数、线程池大小等,以达到最佳的性能表现。
如何优化增删改查?
对于增删改查频繁的场景,一般可以考虑使用以下数据结构:
-
链表:
- 优点: 链表的插入和删除操作都可以在 O(1) 的时间内完成,因为只需要修改指针即可,不需要移动其他元素。
- 缺点: 查找操作的时间复杂度为 O(n),因为需要从头开始逐个遍历节点,效率较低。另外,链表需要额外的指针空间来存储节点之间的关系,空间利用率较低。
-
哈希表:
- 优点: 哈希表的插入、删除、查找操作都可以在平均情况下以 O(1) 的时间完成,具有非常高的效率。
- 缺点: 哈希表的空间复杂度较高,可能会消耗大量内存。此外,哈希表在处理冲突时需要额外的开销,可能会影响性能。
-
平衡树(如红黑树、AVL树):
- 优点: 平衡树的插入、删除、查找操作都可以在 O(log n) 的时间内完成,具有较高的效率。并且,平衡树可以保持树的平衡性,避免出现极端情况下的退化。
- 缺点: 平衡树的实现较复杂,需要维护平衡性,可能会消耗更多的时间和空间。
-
B树和B+树:
- 优点: B树和B+树适合于在磁盘上存储和查询大量数据,能够在较小的树高下存储大量数据,具有较高的IO性能。
- 缺点: B树和B+树的实现比较复杂,需要维护平衡性和节点的顺序,可能会增加额外的开销。
-
堆:
- 优点: 堆可以用来维护最值,插入和删除操作的时间复杂度为 O(log n),适合于需要频繁更新最值的场景。
- 缺点: 堆只能快速访问最值,对于其他元素的访问效率较低,不适合用于一般的增删改查操作。
综合来看,针对不同的应用场景,我们可以根据需求和数据特点选择合适的数据结构。例如,如果需要频繁进行增删操作且数据量不大,可以选择链表或哈希表;如果需要在大量数据中进行快速查找,可以选择平衡树或B树;如果需要维护最值,可以选择堆。
分库分表?
分库分表是一种常用的数据库优化策略,旨在减轻单一数据库的负担,提高系统性能和可伸缩性。
-
垂直拆分:
- 作用: 主要解决不同表之间的 IO 竞争,将不同的表分布在不同的数据库服务器上,减少 IO 瓶颈。
- 方案: 将不同业务功能或者关联性不高的字段分配到不同的数据库中,使得每个数据库只包含特定表的数据,从而减轻单一数据库的负担。
-
水平拆分:
- 作用: 主要解决单表中数据量增长导致的压力,将单表数据分散到多个表中,每个表只包含部分数据,从而提高查询性能和缩短查询时间。
- 方案: 通常根据某个字段进行拆分,比如按照用户ID、时间范围等将数据划分到不同的表中,每个表只包含一部分数据,使得单表的数据量变小,减轻查询压力。
如何设计?
-
垂直设计:
- 字段拆分: 将不常用的字段、大文本字段等拆分到独立的扩展表中,可以减少主表的数据量,提高主表的查询性能。
- 数据频率拆分: 将不经常修改的字段与经常修改的字段分开存储,可以降低主表的更新频率,减少锁冲突和并发访问的竞争。
-
水平设计:
- 取模分表: 对于海量用户场景,可以采用取模分表的方式,将数据均匀地分布到多个表中,避免单一表的数据量过大导致的性能问题和瓶颈。
- 库内分表: 如果数据量继续增长,单库无法承载时,可以考虑在不同的物理机上建立多个数据库实例,每个实例负责一部分数据,从而进一步分散数据库服务器的压力,提高系统的性能和可扩展性。
-
综合考虑:
- 在设计分库分表策略时,需要综合考虑业务需求、数据量、访问模式等因素,选择合适的拆分方式,并进行合理的数据划分,以达到最佳的性能优化效果。
- 同时,还需要考虑分布式事务、数据一致性、跨库查询等新引入的问题,并设计相应的解决方案,保证系统的稳定性和可靠性。
SQL注入?
原理:在HTTP请求中注入恶意的SQL代码,服务器使用参数构建数据库SQL命令时,恶意SQL被一起构造,并在数据库中执行 如何防范? Web端 :有效性检验、限制字符串输入的长度。 服务端:不用拼接SQL字符串、使用预编译的PrepareStatement、有效性检验(防止攻击者绕过Web端请求) 、过滤SQL需要的参数中的特殊字符